一、Pandas 和 Series 的 describe() 方法
1)功能
-
功能:对数据中每一列数进行统计分析;(以“列”为单位进行统计分析)
-
默认只先对**“number”**的列进行统计分析;
- 一列数据全是“number”
- count:一列的元素个数;
- mean:一列数据的平均值;
- std:一列数据的均方差;(方差的算术平方根,反映一个数据集的离散程度:越大,数据间的差异越大,数据集中数据的离散程度越高;越小,数据间的大小差异越小,数据集中的数据离散程度越低)
- min:一列数据中的最小值;
- max:一列数中的最大值;
- 25%:一列数据中,前 25% 的数据的平均值;
- 50%:一列数据中,前 50% 的数据的平均值;
- 75%:一列数据中,前 75% 的数据的平均值;
- 一列数据: “categorical”、“categorical” + “number”:
- count:一列数据的元素个数;
- unique:一列数据中元素的种类;
- top:一列数据中出现频率最高的元素;
- freq:一列数据中出现频率最高的元素的个数;
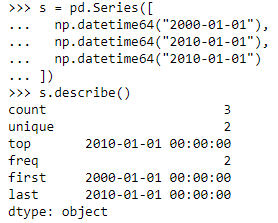
- 一列数据:object(如时间序列)
- first:开始时间;
- last:结束时间;
2)实例及参数使用:Series 数据类型
-
number
-

-
categorical
-
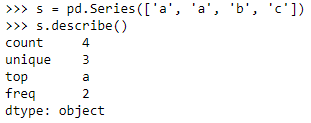
-
object(统称为 “string” 类)
-
3)实例及参数使用:DataFrame 数据类型
-
(一)默认只处理 number
-

-
**(二)**分析整个 DataFrame 数据:include = ‘all’
-

-
(三)指定统计分析 DataFrame 中的某一列
-

-
(四)只分析所有的 “number” 列
-
也可以是:df.describe(include=[‘number’])
-

-
(五)只分析所有 “category” 列
-

-
(六)只统计所有 “object” 列
-

-
(七)分析除了 “number” 列的所有列
-

-
(八)分析除了 “object” 列的所有列
-
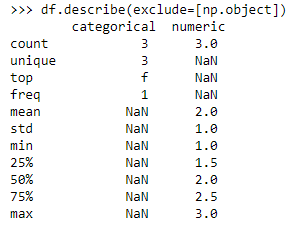
4)与 loc、sort 的配合使用
- df.describe(include=[‘number’]).loc[[‘min’, ‘max’, ‘mean’, ‘std’]].T.sort_values(‘max’)
- 只对数据的“min”、“max”、“mean”、“std”进行分析,并将分析的结果转置后,以“max”的大小对每行进行排序;(默认从小到大)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 水榭听泉!
评论
TwikooGitalk